Designing software is the process to create and define the structure of this software to accomplish a certain set of requirements. Typically the design consists out of different decomposition levels in which the software is decomposed into different entities, which do interact with each other. As such, one could conclude that we will have one design for the software comprehending different decomposition levels. What many people do not realized is, that we do have different types of design, being the intended design and the implemented design.
The intended- and implemented design.
The intended design is the design as it is designed to be implemented. It is the intention that the intended design will be implemented as such in the actual code. Typically, the intended design is the design as it is documented in a tool like Enterprise Architect.
The implemented design is the design as it is actually implemented in the code. In an ideal situation this implemented design will be equal to the intended design. However, this never seems to be the case in practice. Differences will always exist between the intended design and how it is actually implemented in the actual code; the implemented design.
Figure 1 illustrates two components (cubicles) each containing a number of functions (black dots). The lines are interfaces between different functions.
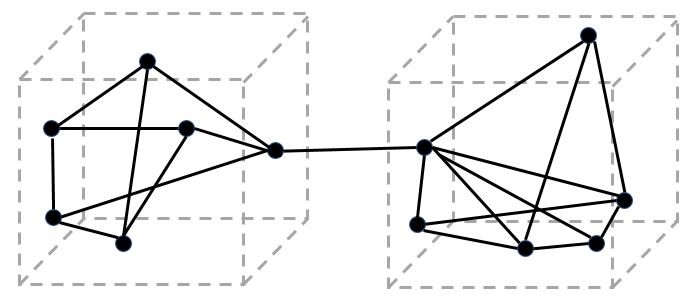
Figure 1
Let’s suppose that the implementation of this intended design is exactly implemented in this way; the implemented design equals the intended design.
Whenever a change is required and a certain function would need data from another function in the other component, the needed communication should be implemented by means of the well-defined interface between the two components. However, it might be decided to directly call this function in the other component without using that interface. If this happens, an unintended interface between the components will be realized (visualized by an additional call between the components). In case this happens multiple times, we will come across a situation as reflected in Figure 2, illustrating the gap between the intended design and the implemented design.
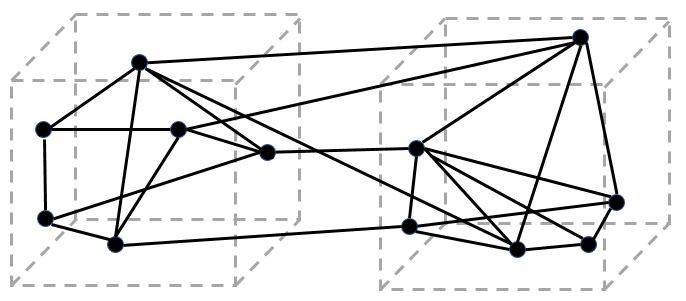
Figure 2
It is obvious that one would need to mitigate the gap between the intended– and implemented design as much as possible.
One can think of several reasons causing the gap between the intended– and implemented design, like an inexperienced engineer not being aware of the intended design, an engineer implementing that hack due to time pressure or even not updating the documentation of the intended design after a necessary change was applied in the code.
The understood design
In “Who needs an Architect?”[1] Martin Fowler stated:
“The expert developers on the software will have some common understanding of how the thing works.
And it is that common understanding which is effectively the architecture.”.
Taking into account that architecture is your highest level of design, this puts a new perspective on the design of a piece of software. Asides the intended design and implemented design, apparently there is something as an understood design; the common understanding by the experts of how the software works.
Experiences
During my career, I’ve seen many situations in which all three design-types were inconsistent with each other. Dependent of the size of the gap between specifically, the understood design and implemented design, unexpected side effects, needed rework and even instable software as a result was experienced. In some cases, in which the gap between the implemented design and the other design-types was huge, the software was not maintainable anymore. Engineers did not dare to ‘touch’ the code anymore, afraid they would break it.
Therefore, it is important to mitigate the gaps between the intended-, implemented and understood design as much as possible by documenting and maintaining the intended design, by sticking to the defined architectural and design rules when implementing and by running static design analysis by reverse engineering tools like Lattix, to get insight in the implemented design.