by Ger Cloudt, author of “What is Software Quality?”
One of the struggles of software development is the assurance of quality. Sure, if you talk about quality assurance, people will refer to testing. Or, one might want to assure quality by applying proper processes and best practices. Process improvement and reference models like ASPICE and CMMi are used in the industry to increase quality or to determine the capability of the organization to develop high quality software. However, when using reference models like ASPICE or CMMi there is a pitfall, using ASPICE or CMMi might disturb the balance between process and skill.
Process and Skill
According to Wikipedia.org a process is defined as “a series or set of activities that interact to produce a result”.
Additionally, to execute a process one needs to have a skill. According to Wikipedia.org a skill is “the learned ability to perform an action with determined results”.
Process and skill are complementary, so you will need both. To execute actions or activities you need a certain level of skill, to achieve a result multiple actions need to be structured by a process. However, the importance of process compared to the importance of skill is dependent on the kind of activities to be performed.
In figure below it is tried to visualize the relevance of process versus the relevance of skill to perform a certain task. On the left side of the figure tasks are positioned for which process is highly relevant and the needed skill-level is relatively low. An example is assembly-line work. Many people are able to perform these tasks as the needed skill-level is low, however the order of activities to be performed are very strict and therefore the process relevance is high. The same applies to building this furniture bought at IKEA. A manual describing how to assemble (process) the cupboard or chair is important whilst the needed skill-level is quite modest.
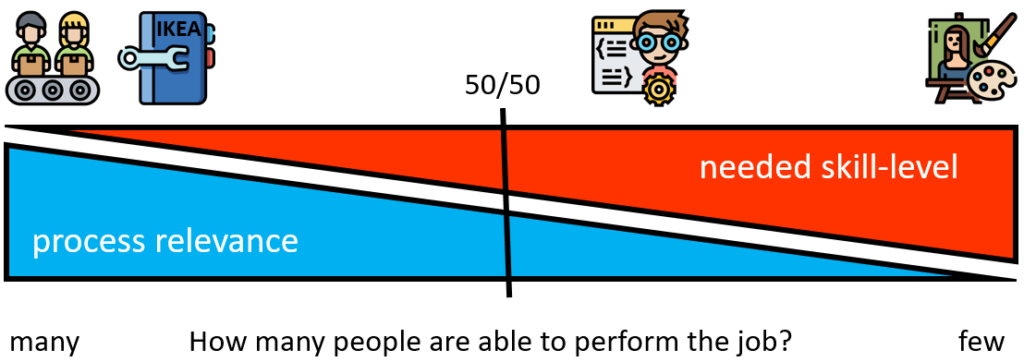
At the other side of the scale we have activities for which process relevance is low but a very high skill-level is needed which only a few people master. An example would be painting the Mona Lisa as Leonardo da Vinci did.
Software Engineer
The question is where to position the software engineer in the figure? If you draw a line reflecting the position at which process relevance and needed skill-level are equal, would the software engineer be placed on the left or right of this line? In my humble opinion the software engineer would be positioned on the right of this line, meaning that I think the needed skill-level is more important than the process for performing the role of software engineer. To put it differently: a process is a tool that helps you apply your skills. If the skill isn’t available, a process doesn’t help you. However, if the skill is available, a process can help to apply this skill.
ASPICE or CMMI level
Process improvement models like ASPICE and CMMI define different maturity levels which are used in some industries as a minimum requirement for software or system suppliers. This requirement or target setting to be process compliant within a certain process reference model disturbs the balance between process and skill.
By setting a target to be process compliant and achieve a certain ASPICE or CMMI maturity level the focus is directed to the less important part in the process-relevance versus needed skill-level balance. Achieving the target-level of process compliance does not tell the full story and therefore there is the danger that it is assumed that the process compliance is equal to achieving high-quality software which it is not. Process compliance assures that defined and necessary activities are performed, however it does not say anything about how well these activities are performed. Therefore, additionally to checking process compliance, one should check the content, the result of the activities, as well. Simply, because for performing the activities well, skills are needed. Good skills will lead to good results, bad skills will lead to bad results.