“The biggest IT-fail ever.” called Elon Musk it on X. He was talking about worldwide problems at July 19th, 2024 caused by an update of CrowdStrike software on Windows systems bringing down airports, financial services, train stations, stores, hospitals and many more. ~8.5 million Windows devices were hit[1] by this software update resulting in crashing computers displaying the infamous Blue Screen of Death (BSOD).
An update by CrowdStrike was released, impacting Windows operated systems worldwide. Soon a workaround was issued which needed manual operation for each individual computer. This workaround prescribed to reboot the crashed computer in safe-mode and consecutively a “C-00000291*.sys” file with timestamp ‘0409 UTC’ in the folder C:\Windows\System32\drivers\CrowdStrike should be deleted or maybe renamed[2].
CrowdStrike
CrowdStrike is an independent cybersecurity company providing security related services. One of the products of CrowdStrike is the so-called “Falcon Sensor” which runs in the kernel of Windows and analyses connections to and from the internet to determine possible malicious behaviour.
Already soon from the workaround as published by CrowdStrike, one can conclude that the update of this specific .sys file caused the failure.
Preliminary Post Incident Review
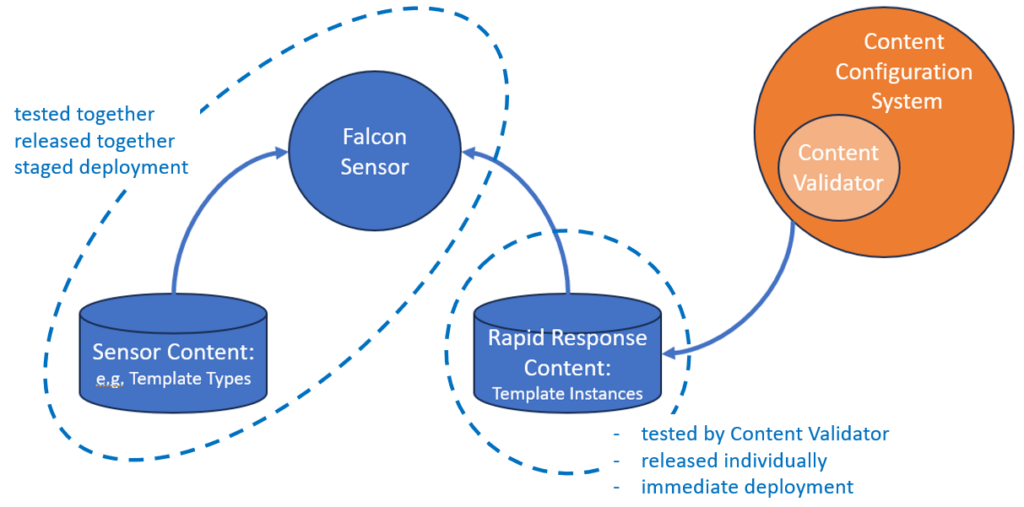
Approximately one week after the failure, CrowdStrike published a preliminary Post Incident Review[3] (pPIR) from which we can learn that the Falcon Sensor software is using two types of content, being ‘Sensor Content’ and ‘Rapid Response Content’. As explained in the pPIR, the Sensor Content is released and deployed in combination with an update of the Falcon sensor itself. The Rapid Response Content contains configuration data that may be updated from the cloud independently from the Falcon Sensor.
Additionally, in the pPIR it is explained how the software and data are tested. The release process of the Falcon sensor, including Sensor Content, starts with automated testing like unit testing, integration testing, performance testing and stress testing in a staged process of which dogfooding at CrowdStrike is part. Before made generally available to customers deployment is done toward early adaptors.
No complex scenario needed
Considering the scale of computers crashed on July 19th, 2024 one would expect that the fault should have been detected during the first stage of deployment, being at CrowdStrike themselves during their dogfooding. It was not a specific complex scenario to be executed to crash the system, one can conclude that whenever the Rapid Response Content file was updated the crash was inevitable. So, apparently the test process for a Rapid Response Content has to be different excluding any stagged deployment.
Rapid Response Content
To understand the test process of a Rapid Response Content update, one need to understand that Rapid Response Content is generated by so-called Content Configuration System software running on the Falcon platform in the cloud. Part of this Content Configuration System is the Content Validator, a piece of software which validates the generated Rapid Response Content.
Blame the test
On July 19th, 2024, the Rapid Response Content files were deployed into production after successfully passing the Content Validator. According to the pPIR of CrowdStrike, problematic content in the Rapid Response Content, which was not as such detected by the Content Validator, resulted in a out-of-bounds memory read triggering an exception.
Apparently the Content Validator was the only test performed on Rapid Response Content before deployment into production and in this particular case it did not detect an error in the Rapid Response Content to be published. No higher level test, testing the combination of the Falcon Sensor and the Rapid Response Content seemed to be performed.
Reading the pPIR it feels like “blame the test” for not finding the bug: the Content Validator failed to detect the bug and no higher levels of testing were performed.
Let’s try to visualize the Falcon Sensor, it’s Content files and the Content Configuration System in the figure below.
Preventive Actions
In the pPIR CrowdStrike presents preventive actions for preventing this happening again. Next to more extensive testing of Rapid Response Content, improvement of the Content Validator and a staged deployment of Rapid Response Content will be introduced. This sounds reasonable, but one could ask the question why these were not already in place? In a proper root cause analysis, like an 8D, this question will be asked.
One preventive action, however, caught my attention: “Enhance existing error handling in the Content Interpreter.”. This because previously in the pPIR it was mentioned that the unexpected out-of-bounds exception could not be gracefully handled. I have the feeling that a formulation like that the unexpected out-of-bounds exception was not gracefully handled would be a better one and enhancement of the existing error handling will encompass the handling of this unexpected exception. However, without knowing the details of the code, this is a speculation.
Problem Areas
Thinking about this problem and what we can learn from it with the information available so far, I would come to three problem areas.
- Testing
- Coding
- Configuration Management
Considering testing, I do agree with CrowdStrike’s analysis in the pPIR. They explain the test process and their proposed preventive actions on testing to improve. However, like already mentioned, I think they need to understand why the obvious proposed preventive actions for Rapid Response Content were not in place already?
About the coding part, I would be very curious to see the actual code where the out-of-bounds exception happens. Is the memory location immediately accessed or is there any form of a validity check of the memory address to be accessed before actually accessing? Is there any mechanism, like a catch (exception handler), in place to catch the thrown exception? How will the pronounced enhancement of the existing error handling look like? What can be learned by the engineers considering unexpected exceptions in other places of the code?
Maybe you are surprised that I bring up configuration management as a problem area. Looking at the visualization of the Falcon system (including the Content Configuration System) I do recognise different parts with a different update cycle. The Falcon Sensor in combination with the Sensor Content next to the Content Configuration System with the generated Rapid Response Content. As explained in the iPIR, the Rapid Response Content contains so-called Template-Instances whilst the Sensor Content contains Template-Types. I can imagine that the Template-Instances need to be compatible with the Template-Types. This is a configuration management problem. I did not read anything about configuration management in the iPIR, so I hope CrowdStrike is in control of this. Are we sure the right version of Template-Types was used when the Content Configuration System generated the faulty Rapid Response Content file?
Looking forward to the full Root Cause Analysis by CrowdStrike.
[1] https://blogs.microsoft.com/blog/2024/07/20/helping-our-customers-through-the-crowdstrike-outage/
[2] https://www.ncsc.nl/actueel/nieuws/2024/juli/19/wereldwijde-storing
[3] Falcon Content Update Remediation and Guidance Hub | CrowdStrike